Priority queues are one of the data structures that have intrigued (and confused) me the most. Its implementation is different from many tree-like data structures, and its inner processes seem to be different from other structures like balanced binary trees. This is why I've put some time into building one myself and getting familiar with the inner workings of this popular data structure.
According to the great Wikipedia, a priority queue (or heap) is defined as follows:
"A priority queue is an abstract data type similar to a regular queue or stack data structure in which each element additionally has a priority associated with it. In a priority queue, an element with high priority is served before an element with low priority."
Basically, in a priority queue, you insert elements and when you pull out those elements, the ones with the highest priority will exit first.
Priority queues are also called heaps, and they come in two flavors: min heaps and max heaps. As their name indicates, the priority in which elements are extracted is their value: For min heaps, the smallest elements come out first, whereas, for max heaps, it is the largest elements the ones that come out first.
So, when we talk about "higher priority", for min heaps it means the elements are smaller, and for the max heap, it means that the elements a larger.
For instance, if you insert the following numbers -in that order-: 3,5,6,2,9,1 into a min heap, if you pull them out one by one, you will get them in ascendent order: 1,2,3,5,6,9. The order would be reversed if this was a max heap.
Priority queues have multiple applications: finding the largest/smallest N elements in a list in almost linear time, keeping track of processes with high priority in a multi-process application, or even sorting a list of elements in O(nlogn) time.
While the generalized advice is to always use data structures that are well-tested and already included in most coding languages, learning the inner workings of heaps helps us decide whether this data structure is the correct one for our use case. In short, there is rarely a case where you want to implement your own data structures when you are already getting them for free.
Having said that, before jumping into the implementation details, to understand how priority queues work we need to underline some specific facts about them.
Properties
Internally, priority queues have two key properties:
- Each element in the heap has two or fewer children, and the children must be of a smaller or equal priority than their parent.
- There is only one single root element: The one with the highest priority.
As long as our heap maintains those properties, we're free to use the implementation details we wish (though, as we will see, the most common implementation tends to be optimal).
Another property can be seen, though there are implementations of heaps that don't necessarily follow this property:
- When represented as a binary tree, the heap is a complete tree.
Priority queues are commonly stored in arrays, but they are structured like trees
If you look at any implementation of a heap, you will find that it is structured like a binary tree: It has "nodes" and each node has two "children" that have strictly less or the same priority as the parent node.
In practice, the heap is stored in a list or array. Each element in the list is a node, and to find each node's children, we employ a clever trick: The left child is given by solving the formula l = i*2 + 1, where i is the index for the parent node, and the right child is given by r = i*2 + 1.
The following two images show how elements 0 and 1 find their children in the list. Element 0 of the array finds their children in indices 1 and 2

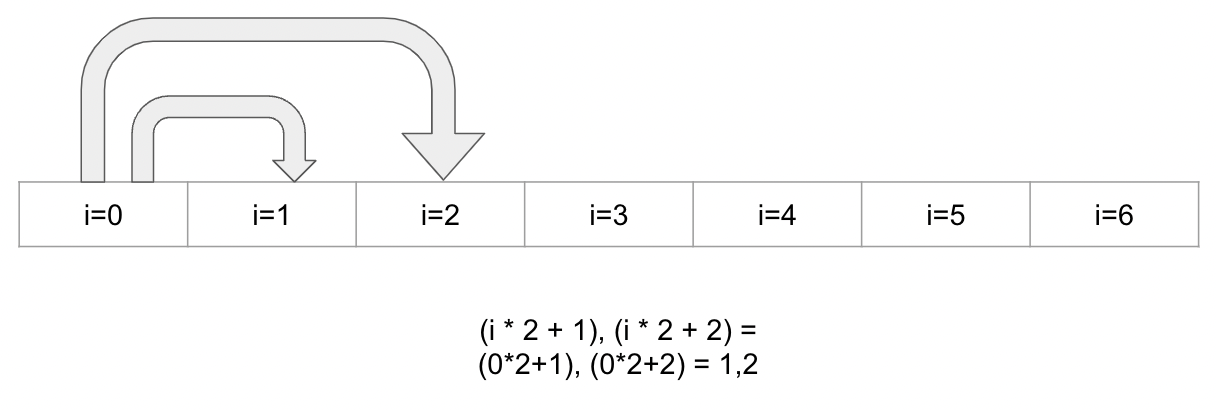
And element 1 of the array finds their children in indices 3 and 5

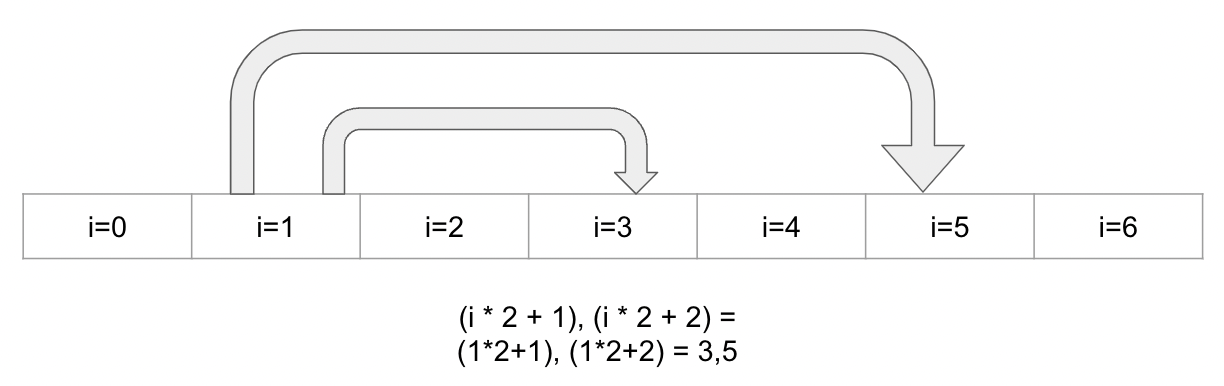
When calculating the index for the children for a given node, it's critical to remember that the children may not exist in the list (think of the case where the heap has only one element), and we must check the list's length before retrieving the nodes to avoid getting an index-out-of-bounds error.
Why not just use a tree instead? Trees have the added memory overhead of having to keep pointers or references from one node to its children. And, since the "tree" will always be complete, an array or list will be the most efficient way to store the elements in the priority queue.
Priority queues don't keep a sorted list of elements
Since we can sort a list by adding all their elements into a heap and pulling them out one by one, it is easy to think that those elements are internally ordered. This is not true.
All that heaps care about is keeping track of the largest or smallest element at any time. When we add or remove elements from the heap, it will internally reorganize its contents to make sure that the new largest/smallest element is now at the top of the heap.
However, heaps do keep a specific order in their elements. When seen as a tree, for each node in the heap, all its children will be of a lower or equal priority than the node's value. This ordering brings a good property: The first -smallest/largest- element will always be the first element in the heap's internal array.
Finding the top element in the heap is O(1) fast, but adding or removing elements is less fast -O(logn)-
Since we know the heap will always keep the largest element in the first element of its internal array, finding the element with the highest priority is as easy as reading the first element.
But this guarantee -the largest/smallest element being at the top- comes from the fact that the queue keeps moving its elements around when we add or remove new elements.
For instance, if a min heap had only two elements, [2,3] finding the smallest is fast. In constant time -or O(1)- we just poll the element at index 0. However, if we insert another number, there is no guarantee that the first element will be the smallest anymore: If we insert a 1, the heap will re-order its contents to something like [1,3,2]. As we can see, the heap keeps its properties (the first element is the smallest, and its children are larger than it), but this re-ordering comes at a price.
A performant heap will re-order its elements on insertions and deletions in O(logn) time (more details on why below). This is why sorting elements using a heap (also called "heap-sort") takes O(nlogn) time: We insert n elements, and each insertion takes O(logn) time to re-order the heap to keep its properties.
In practice, heaps can store any comparable value
While most examples of heaps deal with numbers, in real-life applications heaps can hold references to complex data structures like objects. The only requirement is that these data structures are comparable: We can take two instances of these data structures and quickly (in constant time, preferably, or else the heap loses all its performance properties) determine which one has a higher priority. For numbers it's easy (compare their values), but other, more complex structures, need to provide a way to compare two elements: Comparing one of its attributes, like a "priority" or "order" value, or any similar method.
Now that we understand the key facts of priority queues, let's look at their inner workings.
The API
For the sake of simplicity, we will only allow numbers in our heap. If we wanted to allow any kind of object, we would have to modify the parts of the code where we compare elements to use a comparator function, provided by the consumer of the heap class. We also assume that the heap cannot store null values, as they cannot be compared (we will use null as a special value to move elements around during each operation; more details to follow).
We will define a JavaScript class with the expected interface for a heap:
class Heap {
/**
* Add an element to the heap
* @param {number} el - the element to add
*/
push(el) {}
/**
* Read the element with the highest priority
* without removing it from the heap.
*
* @returns the value of the element with the
* highest priority
*/
peek() {}
/**
* Read the element with the highest priority
* and remove it from the heap.
*
* @returns the element with the highest priority
*/
poll() {}
}
As the comments at the top of each element, the heap will have three basic operations:
- Push. Add elements to the heap
- Peek. Reading the top element, without removing it from the heap
- Poll. Reading the top element, removing it from the heap
Peek
We begin with the simple case of all: peek.
We define an array for the contents of the heap, and when we peek at an element, we will return the first element of such array:
class Heap {
content = []
peek() {
if (this.content.length === 0) {
return null
}
return this.content[0]
}
If the content is empty, we return either a null value. We may throw an exception too, but I think it's more user-friendly to not force consumers to handle exceptions for an operation that does not break anything.
Time complexity
This operation is the fastest of all. It takes constant time -O(1)-, since we don't need to search for the top-priority element in the heap. It's always at the top.
Push
For the push operation we will do a couple of things:
- We add the element at the end of the
contentarray. - Iteratively, we swap the new element with its parent until we find its correct place in the heap.
/**
* Add an element to the heap
* @param {number} el - the element to add
*/
push(el) {
this.content.push(el)
this.size += 1
this._reorderElements(this.content.length - 1)
}
The implementation of this._reorderElements requires us to find the parent of a given node. To do so, we will use the inverse of the formula we previously defined for finding a node's children:
- If the index is an even number (e.g. 2), we find the parent at
elementIndex / 2. - If the index is an odd number (e.g. 3), we find the parent element at
(elementIndex - 1) / 2.
You can run examples on these formulas and you will find that they indeed return their correct parent.
The following function will allow us to find the parent for a given node:
/**
* Find the parent element of a given node
*
* @param {number} elementIndex the index of the child node
* @returns the index for the parent
*/
getParent: function (elementIndex) {
if (elementIndex == 0) {
return null
}
if (elementIndex % 2 > 0) {
return Math.floor(elementIndex / 2)
}
return Math.floor((elementIndex - 1) / 2)
},
Notice that, if the element index is already 0, we return null, as the first element has no parent.
Going back to the push method: We use JavaScript's Array method push to add to the end of the array, then we call the sub-method this._reorderElements on the last element index (this.content.length - 1).
/**
* Reorder the heap contents to make sure the element at
* elementIndex is in the right place.
*
* @param {number} elementIndex
*/
_reorderElements(elementIndex) {
let elementVal = this.content[elementIndex]
let parentIndex = HeapUtils.getParent(elementIndex)
while (parentIndex !== null) {
if (this._shouldSwap(this.content[parentIndex], elementVal)) {
HeapUtils.swap(this.content, parentIndex, elementIndex)
elementIndex = parentIndex
parentIndex = HeapUtils.getParent(elementIndex)
} else {
break
}
}
}
/**
* Compare elements and return if we should swap elements
*
* @param {number} parentValue
* @param {number} elementValue
* @returns true if the elements should be swapped
*/
_shouldSwap(parentValue, elementValue) {
return this.isMaxHeap
? parentValue < elementValue
: parentValue > elementValue
}
Let's unpack what the _reorderElements function is doing:
- We get the value of the element at
elementIndex. - We find its parent's index and its value in
content. - Iteratively, we perform the following steps:
- If
elementIndexis the first element,getParentwill returnnull, so we don't enter the loop. - We compare the parent's value with the element's value. If they are in the right order, we just stop the loop.
- If they are not in the right order, we swap their values and we update
elementIndexto point to its new location (where its parent used to be); we then find its new parent.
- If
What this function achieves is to move up the new element until it's located in its correct place. At each step, we don't need to check the parent's current children, as we know for sure that the parent will be larger or equal in priority.
Time complexity
How many iterations does this function take? At most, we do as many swaps as the tree's height. Since the content is structured as a balanced binary tree (a property that comes from being a complete tree), we know that the tree's height is logn where n is the number of elements in the tree.
So, it follows that the time complexity for the push operation is O(logn).
Poll
The poll operation is slightly more complicated. We will perform the following steps:
- Get the value of the first element in
content. - Mark the first element for deletion. In this implementation, we do so by setting its value to
null. - Move the
nullelement down the heap, swapping it with one of its children (the one with the highest priority). - Stop until the
nullelement is at the end of the array.
/**
* Read the element with the highest priority
* and remove it from the heap.
*
* @returns the element with the highest priority
*/
poll() {
if (this.content.length === 0) {
// optionally, throw and exception
return null
}
const result = this.content[0]
this.content[0] = null
HeapUtils.heapifyOne(this.content, 0, this.isMaxHeap)
if (this.content[this.content.length - 1] === null) {
this.content.pop()
}
this.size -= 1
return result
}
The first lines take care of retrieving the first element from contents. In this case, we might want to throw an exception, as this operation is expected to update the contents of the heap.
We set the first element's value to null and then we start to re-order the heap with the function heapifyOne:
/**
* Heapify on just one element at startIndex
*
* @param {array} content
* @param {number | null} startIndex
* @returns
*/
heapifyOne: function (content, startIndex, isMaxHeap) {
if (startIndex === null || startIndex >= content.length) {
return
}
const [left, right] = HeapUtils.getChildren(content, startIndex)
// If both are null, no need to swap elements
if (left === null && right === null) {
return
}
// If one of the children is null, swap the parent with
// the one that is not null
if (left === null || right === null) {
HeapUtils.swapAndHeapify(content, startIndex, left || right, isMaxHeap)
return
}
function getElementToSwap() {
if (isMaxHeap) {
return content[right] > content[left] ? right : left
}
return content[right] < content[left] ? right : left
}
function isLeaf(index) {
const children = HeapUtils.getChildren(content, index)
return children[0] === null && children[1] === null
}
let d = getElementToSwap()
if (d === left) {
const leftc = isLeaf(left)
const rightc = isLeaf(right)
if (leftc && rightc) {
HeapUtils.swap(content, left, right)
d = right
}
}
HeapUtils.swapAndHeapify(content, startIndex, d, isMaxHeap)
return
},
}
This function makes use of several helper functions, which are defined below:
/**
* Find the indices of the child elements for a given parent.
* The indices can be null if:
* - The index is out of bounds
* - The value of content at the index is null
*
* @param {array} content the list of elements
* @param {number} parentIndex the index of the parent element
* @returns [number | null, number | null], for the indices of both children.
*/
getChildren: function (content, parentIndex) {
const left = parentIndex * 2 + 1
const right = parentIndex * 2 + 2
function getValidChild(index) {
if (index < content.length && content[index] !== null) {
return index
}
return null
}
return [getValidChild(left), getValidChild(right)]
},
/**
* Swap the values of two indices
*
* @param {array} content - the list of elements
* @param {number} index1 - element 1
* @param {number} index2 - element 2
*/
swap: function (content, index1, index2) {
const t = content[index2]
content[index2] = content[index1]
content[index1] = t
},
/**
* Swap two elements at startIndex and otherIndex,
* then heapify on otherIndex
*
* @param {array} content
* @param {number} startIndex
* @param {number} otherIndex
*/
swapAndHeapify: function (content, startIndex, otherIndex, isMaxHeap) {
HeapUtils.swap(content, startIndex, otherIndex)
HeapUtils.heapifyOne(content, otherIndex, isMaxHeap)
},
Let's break down the heapifyOne function.
This function is called heapifyOne because it will only re-order the elements in the tree that are descendants of startIndex. It's important to make this distinction because you will find that some implementations of heapify will check all the elements in the heap to make sure they are in their right place.
This distinction is what makes our heap more performant: We assume that at any given moment the heap has the right order. It's only during push or poll that we need to change the element's order, but in those operations, we can focus only on the ascendants (parents) or descendants (children) of the elements being added or removed. We don't need to check the rest of the elements because we know they will be in the right place.
Note: The common implementation of heapify is useful to build priority queues out of unordered arrays in place. In our implementation, we can do the same thing by inserting one element at a time out of the unordered array. The downside of our implementation is that it requires us to copy the array into the heap. If you need to performantly convert existing arrays into heaps, it's better to use a regular implementation of heapify.
The first step in heapifyOne is to check if startIndex is valid (non-null and within the range of content). If it isn't, we stop.
Then we find the children elements of startIndex. Here, there are a couple of cases we need to address:
- The element has no children. In this case, we don't need to swap any elements, as we reached the bottom of the array.
- The element has only one child. This happens if there are only two elements in the heap, or if the element is almost at the bottom of the tree/array. In this case, we swap the element with the existing child; we don't need to compare values as we know that the parent is
nulland needs to be moved to the bottom. - The element has two children. In this case, we swap the
nullelement with the child with the highest priority, guaranteeing that the heap keeps its properties. - After swapping the elements, we recursively apply
heapifyOneto the new position of thenullelement. This recursion will stop once we reach the bottom of the heap.
Let's give some more thought to the case where the null element has two children. Why don't we need to re-order this whole sub-tree?
When we swap the null element with the child with the highest priority, the whole sub-three -except the null value- still retains its properties. We know that each child has a lower or equal priority than its parent, so moving up one of the children -let's say the left one- will not affect the order of the other children. The following image shows this process:

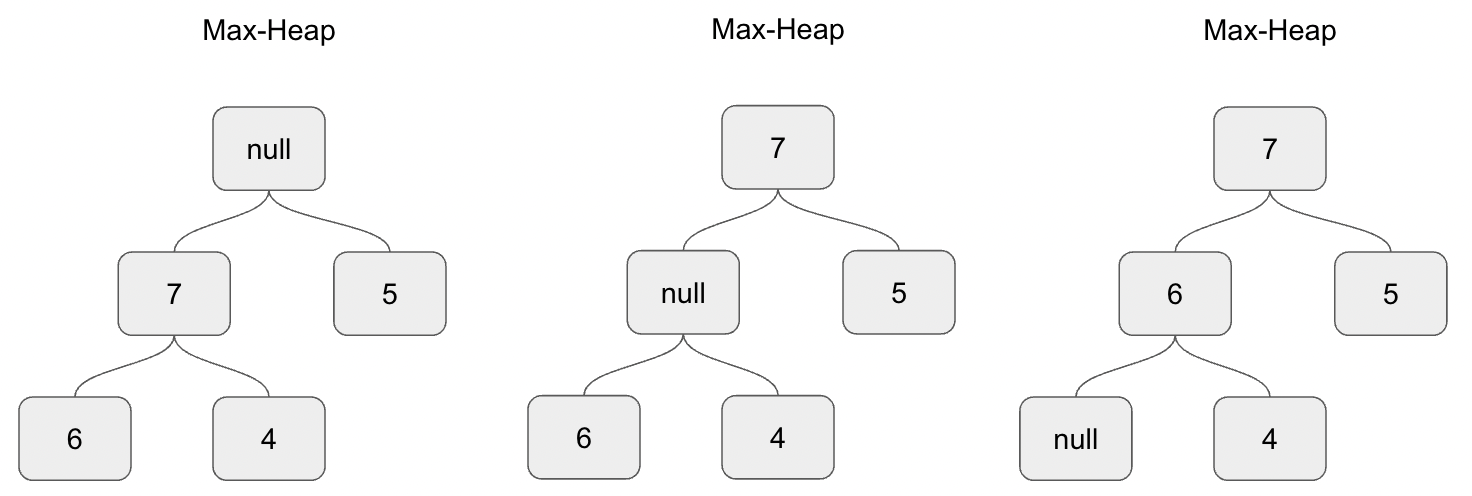
Notice a small contradiction here. In the image above, the generated tree is not strictly complete. The deepest sub-tree has a null value in its left child and a valid element in the right child. We cannot just swap the null child with the other non-null child, because the non-null child may have children on their own.
These null "holes" happen in a very specific condition:
- The
nullnode has two children. - The two children are not
null. - The chosen children to be swapped with
nullis the left node. - Both children are "leaf" nodes: They have no children on their own.
The following code from heapifyOne takes care of amending these "holes":
function isLeaf(index) {
const children = HeapUtils.getChildren(content, index)
return children[0] === null && children[1] === null
}
let d = getElementToSwap()
if (d === left) {
const leftc = isLeaf(left)
const rightc = isLeaf(right)
if (leftc && rightc) {
HeapUtils.swap(content, left, right)
d = right
}
}
HeapUtils.swapAndHeapify(content, startIndex, d, isMaxHeap)
If we find that the chosen node to swap with null is the left child, we check if both are "leaf" nodes. If they are, we can safely swap the values of both children and swap the null value with the right child (which now has the value of the left child).
This simple process guarantees that the null value will be placed at the right child of the bottom sub-tree, keeping the properties of the heap without having to re-order the whole tree.
The heap would still work without amending these "holes", but the inner content array could grow more than needed, keeping a lot of null values between valid elements.
Once heapifyOne completes its recursive execution, the null element will be at the bottom of the heap, and we can safely remove it from content with content.pop().
Time complexity
The number of swaps we need to perform to move the deleted node from the heap is at most, again, the height of the tree, or O(logn).
Time complexity: Heap sort
As we mentioned before, we can sort a list of numbers by adding each number to the heap and then pulling them out. We can break down this process of "Heap-sort" into parts:
- Number of
pushoperations:n, wherenis the number of elements in the list. - Number of
polloperations:n.
Since each push and poll operation takes O(logn), the whole sorting operation takes O(nlogn) + O(nlogn), which can be reduced to O(logn), the same time complexity of other stable sorting methods like merge sort.
Challenge: Finding the K largest elements
To complete this post, let us look at a common use for priority queues: Finding the K largest elements in a list.
We can break this problem down into simple steps:
- We iterate through each element in the list called
numbers. - Using a min heap (more details on this counter-intuitive choice to follow), we keep track of the largest elements in the list.
- If the size of the heap is smaller than
K(the number of largest elements to find), we just push the number to the heap. - If the size of the heap is equal to or larger than
K(meaning we already haveKnumbers in the heap) and the new number to add is larger than the element at the top of the heap, we remove the smallest element in the heap and push the new number. This is why we chose a min heap in this problem, to quickly locate the smallest value and replace it with the new, larger number.
function nLargestNumbers(numbers, K) {
const heap = new Heap()
for (const num of numbers) {
if (heap.size < K) {
heap.push(num)
} else {
if (num > heap.peek()) {
heap.poll()
heap.push(num)
}
}
}
return heap.content
}
console.log(nLargestNumbers([1, 4, 2, 4, 5, 6, 3, 9, 1], 3))
// result: [5, 6, 9]
Time complexity for "Finding the N largest elements" using a min heap
In the worst case scenario where the numbers are sorted in ascendent order, the overall time complexity will be O(log(n)), where n is the number of elements in the list numbers. This is because at every iteration we will have to push a new element into the heap, which takes O(logn). As you can see, this is no better than just sorting the numbers and getting the last (or first) K elements.
However, in average, using a heap will perform fewer operations than any sorting algorithm: If the top K elements are near the beginning of the array, once the heap contains them it will not have to do any more push or poll iterations. In the best-case scenario where the first K elements are at the beginning of the array, the overall time complexity using a priority queue will be O(KlogK) + O(n-K), which approximates O(n) as K gets smaller.
Another scenario for this problem where priority queues will perform consistently better is where the list of numbers is not given at once. If the method is expected to receive one element at a time, using something like merge-sort will require n sort operations, or n*O(logn), whereas the priority queue will take O(nlogn) consistently.
Visualizing a priority heap, step by step
As a bonus, here is a step-by-step animation of the priority queue we just implemented. Feel free to play with it, changing configurations and playing back and forth the animation using the slider.
See the Pen CSS variables and dark-mode by Pedro Marquez (@pfernandom) on CodePen.
Conclusion
Priority queues are simpler than they seem. As long as we maintain their main properties (each child of a given element is of a lower or equal priority as the element, and there is only one single root element, and the push and poll operations can be done in O(log) time), any method that we use to update the priority queue will work.
The implementation we saw here does minimal work to fulfill the definition of a priority queue. Other implementations may include keeping the order of insertion when elements have the same priority or keeping track of the top K elements in constant time by guaranteeing that the direct children of each node are ordered from left to right.
I hope this post makes things clearer for you next time you think about using priority queues. Understanding a tool a little better makes us more comfortable using it.

