In the past weeks, I've been playing with Convolutional Neural Networks (CNNs). Specifically, I've been building different variations of denoising autoencoders to see if they would be a good, less memory-intensive option to Generative Adversarial Networks (GANs) to reduce pixelation in old videos.
The first iterations of the model had a lot of trouble recovering details like small pieces of text from the images. Then, I found that the UNet architecture does a good job of preserving those kinds of details for segmentation tasks, so I thought of using this concept of feeding forward previous layers and seeing if that would improve the image resolution.

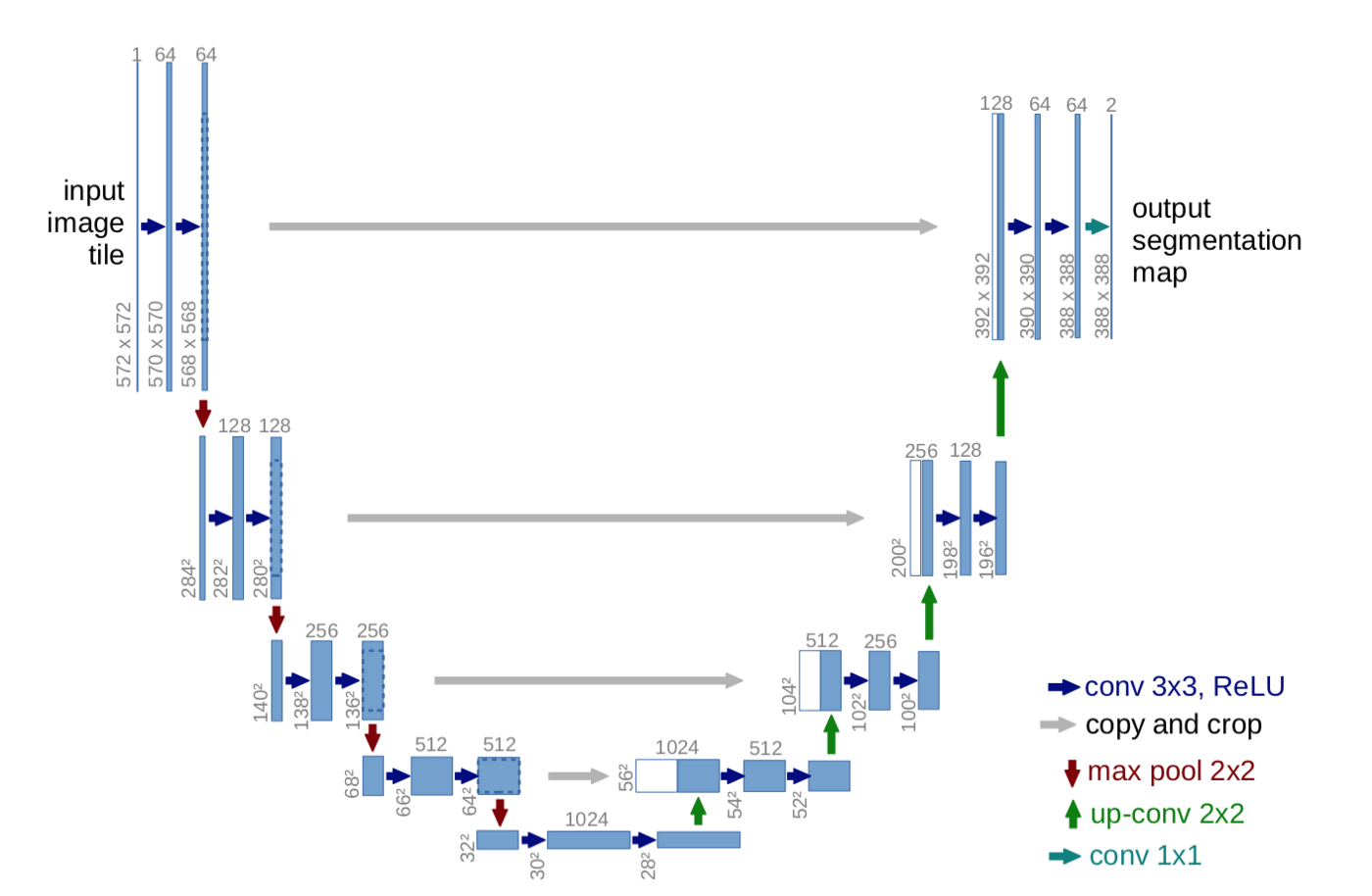
This change in the model introduced a second challenge: The model was now overfitting, fully ignoring the convolutional layers originally built for the autoencoder and taking all the input from the feed-forward layers. The mean squared error would lower quickly and then flatten.
The model was basically just taking the input image and spitting it out without improvements.
Preventing overfitting: Dropout
A common solution for preventing overfitting is to introduce Dropout layers that will drop a fraction n of the weights in the previous layer, forcing the model to learn to recognize patterns to keep minimizing its loss function. So I introduced some instances of tf.keras.layers.Dropout with small dropout rates in the first layers of the model, and some other Dropout layers with larger rates in the feed-forward layers.
The result was that the accuracy for the validation set increased slightly, and the validation loss graph went down a bit more, but the training time per epoch went up by more than double. Not the results I was expecting.
Then, while stumbling around Tensorflow's documentation for ideas on what to do next with this problem, I found tf.keras.layers.SpatialDropout2D. The documentation for this layer as a simple, yet clarifying note:
This version performs the same function as Dropout, however, it drops entire 2D feature maps instead of individual elements. If adjacent pixels within feature maps are strongly correlated (as is normally the case in early convolution layers) then regular dropout will not regularize the activations and will otherwise just result in an effective learning rate decrease. In this case, SpatialDropout2D will help promote independence between feature maps and should be used instead.
So there you have it. While I haven't finished my experiments yet, after substituting the regular Dropout layers with SpatialDropout2D, time per epoch down, accuracy and, loss rates stabilized considerably and I'm finding better results in the denoised images.
TLDR: Don't use regular Dropout layers to avoid overfitting in Convolutional Neural Networks. Use instead SpatialDropout2D, which seems to be created specifically to drop complete feature maps instead of individual weights. Dropout only results in reduced learning rates with no real improvements for the model.

